In Part 1 of OOPs and Clean Code, we covered the Principles of Object Oriented Programming. In Part 2, we talk about the dos and don’ts of writing clean code with OOPs.
Writing clean code with OOP (Dos and Don’ts)
Object Oriented Modelling
Object oriented modelling designing your system using objects and relationships between objects. This makes the system resemble the real world, as you’ll be modelling the system inspired by real world objects. This is the purpose of object oriented programming to begin with.
This means before you start writing code, you have to identify the objects (or classes to be more precise) that are relevant to the domain. For example, suppose you’re designing an e-commerce app. You’ll have classes such as Customer, Shopping Cart, Order, etc. This makes complete sense, even to a new engineer who is hired laterally into the project. This is what makes OOP so powerful.
There is no one right way to model a project with classes and objects. Every engineer will conceptualize the same problem in different ways. Usually, you all sit together and decide on one model which satisfies everyone involved in the project. Getting this understanding of the modelling before starting development is very important, as it helps in writing the code better, which will tie up neatly into the next Do in OOP.
Avoiding Duplication Of Code
If you have worked on any fairly long-lived project which involves many developers, you would have seen multiple methods in multiple classes which would be performing the same operation. For example, I have seen many projects that have the same string manipulation method in multiple service classes.
The issue with this is, when you have to change the logic of that string manipulation, you have to hunt down all the methods that are performing that particular string manipulation and change all of them. Even if you miss one such method, your users will not have a consistent experience.
How to avoid this? It’s simple, have utility classes to hold these common methods, which can be invoked from anywhere within the project. This guarantees that the result will be the same no matter where you use this, it becomes predictable. Plus, if you have to change the logic, you do it at just one place. This makes maintaining the code so much easier.
This principle is popularly known as Don’t Repeat Yourself, or DRY. When you have well defined classes with specific behaviour built into them as methods, you will notice that the need for utility classes will be reduced greatly. And since these methods are within the class itself, you’ll not find any reason to duplicate the code elsewhere.
A Class Should Do One Thing
I mentioned in the previous section that you should include all behaviours of a class within the class itself. That doesn’t mean that you just dump all necessary methods into one single class. A class should be a virtualization of a real-world object, and the methods within that class should be related to only that real-world object.
For example, suppose you’re building a car racing game. You have a player object who performs operations such as actuating the throttle, the clutch, the brakes, and the steering wheel of the car. It is not acceptable to have methods such as steer(), accelerate(), brake(), etc. in the Player class. Why? Well, because these are methods related to the car, not the player.
If you add this logic into the Player class, which you can, your Player class is doing more than one thing. Being a Player class, it is expected to perform operations related to only the player, not the car. You can imagine how this might confuse a new developer coming into the project.
I have seen a lot of such bad design in real-world code which handles millions of dollars worth of transactions every day. Take a look at the code snippet in figure 6 below and guess what’s wrong here.
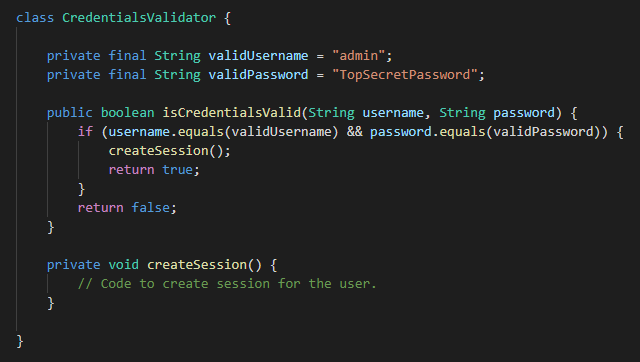 Figure 6: Example of a method doing more than one thing
Figure 6: Example of a method doing more than one thing
Apart from the fact that the credentials are very hard to crack and securely stored (sarcasm alert), you don’t see anything unusual, right? Well, you’re wrong if you thought so. The first method in the class, isCredentialsValid(), should be responsible for checking if the provided username and password are valid or not, according to the name at least. But the implementation tells a different story.
The method, after validating the credentials, is actually creating a session for the user. The class calling this method from another place in the codebase will have no idea that a session was created for this user, and will go ahead to create another session. There would be two sessions for the user. Also, if another part of the code is calling this method for a second validation after the user is already logged in, there would be another session for the user. So in some cases, there would be three sessions for one user.
This method is clearly doing more than one thing. This is against the Single Responsibility Principle (SRP). Even though you could rename the function to checkCredentialsAndCreateSession(), it would still be doing more than one thing. This is a bad practice and should be avoided.
Designing Maintainable And Extendable Code
Usually when we write a new piece of code, we think about the use case that we’re writing for and make the code work for that use case. We don’t think how this could be extended in the future to either add new functionality or improve the existing functionality. If you are modifying an existing functionality, it means that you are modifying existing code. As and when you cram new lines of code into the same functionality, the code becomes more and more difficult to maintain.
There’s a principle that Uncle Bob coined as part of the SOLID principles called Open Closed Design. It states that code should be open for extension and closed for modification. It’s tricky to understand at first, so let’s look at an example to understand better.
We talked about the Shape classes earlier, and we’ll build on the same example here. Instead of an abstract class, the Shape class is now more concrete and has a method to render various shapes. Figure 7 below shows the new implementation.
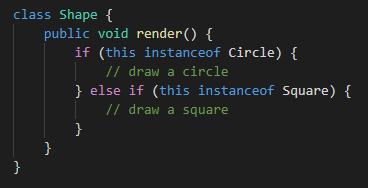 Figure 7: Shape class with a new
Figure 7: Shape class with a new render() method
There are two more classes, Circle and Square, that extend this Shape class, which can be seen in figure 8 below.
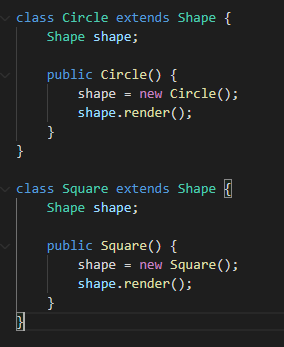 Figure 8: Circle and Square classes extending Shape
Figure 8: Circle and Square classes extending Shape
As you can see from figure 8, the Circle and Square classes instantiate an object in their constructors and call the render() method on those objects to draw them. During your development, this was the requirement. You write the code, test it well, and ship it. After a month, you get the requirement to add a triangle to this mix. Well, that’s not difficult, true. But that would mean you have to modify a piece of code that was already tested for the functionality, which is the render() method in the Shape class. Even though you’re not adding any new functionality to the method (it would still be drawing a shape), you have to modify it.
The Open Closed principle states that the code should be closed to such modifications. The best way to handle this is to either write your code against interfaces, or use abstraction (as discussed earlier) wherever possible.
However, the principle also states that the class is always open for new functionality. You can always add new methods to the class.
Dependency Inversion
Let’s start this one with an example. Figure 9 below shows a pretty basic Java program which is accepting some arguments during boot, and then logging the first argument to a file. The program is using a FileLogger class to log all messages to a file. It’s pretty basic.
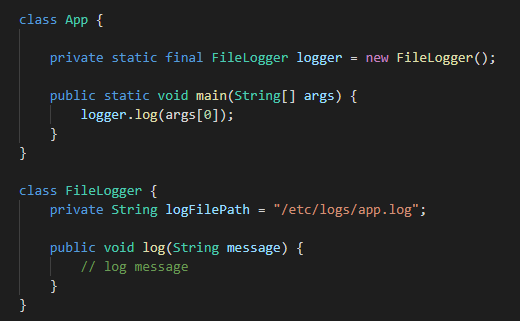 Figure 9: Example of dependency
Figure 9: Example of dependency
But tomorrow, you decide that logging everything to files is taking too much storage space, and you want to switch to a log aggregation service instead of a local file logger. What do you do? Well, you just change the App class to use a new logger. Even though the solution is simple, you still are making changes to tested code and not adding any new features. This is because the App class has a hard dependency on the FileLogger class.
You can make this better by using the dependency injection principle, where you delegate the task of creating objects that your class needs to the framework. You tell your framework that in the App class, you need a logger. The framework creates an instance of the logger class that you choose, and then injects that instance into your App class. You can tell the framework which logger class to inject as well.
This way, if you decide to change the logging implementation in your project, you only need to change one configuration which tells the framework to use the new implementation. And magically, all your classes that use dependency injection will start using this new logger class, without any changes to the classes themselves.
Using dependency injection will allow you to change major parts of your projects – such as logging strategies, databases, etc. – easily without almost any code change.
Composition VS Inheritance
I have seen many developers and authors proposing that composition will soon replace inheritance in object oriented programming. I’ve heard arguments about the opposite as well. But you need to understand, inheritance is very fundamental to OOP, and composition is as well. Even though some inheritance use cases can be replaced by composition (and should be), not all can be. And in most cases, composition is the right way to go.
Let’s look at the car racing game that we talked about earlier. We’ll extend that example (pun intended) to see when to choose inheritance and when composition is the better choice. In your game, you’ll obviously have more than just one car. But it’s not logical to build all of them from the ground up, you want to extract all the common code and place it in a base class, let’s call it the Car class. Next, you can extend this class and build classes such as Ford, Ferrari, McLaren, Honda, Koenigsegg, etc. These are all cars which can all have the same properties and methods as the base Car class, obviously overriding the methods wherever necessary.
Also, all these cars are composed of other parts such as an engine, wheels, windows, doors, etc. You’ll be modelling these parts as classes as well, because they have properties and methods too. But would you say a car extends an engine? Or a car extends wheels? That makes no sense.
If you forget that you’re writing code and talk just about cars, you’d say that a Ford is a car, a McLaren is a car. But you’d never say an engine is a car, or a car is a wheel. Rather, a car has an engine, and a car has wheels. You can clearly say that there’s a “is-a” relationship, and a “has-a” relationship. Both are equally important. The “is-a” relationship is achieved by inheritance, while the “has-a” relationship is achieved by composition. So in the base Car class, you’ll have properties such as an Engine, instances of Wheel, Door, etc. You can now say that your Car class is “composed of” all these other classes.
From this example, it should be clear that you can’t really replace inheritance with composition, or the other way around. At the same time, you should be able to decide when to use what. If you’re following object modelling properly to mimic real world objects, you shouldn’t find making this differentiation difficult at all, it’s pretty straightforward and logical.
Conclusion
To reiterate what I said at the start, writing clean code is an art. And as with any art, it takes a lot of studying, practice, explorations and eventually finding your own way of solving problems through code, to master the art. The dos and don’ts listed here should serve as a good starting point. But this isn’t an exhaustive list or a complete one; this is just a getting started guide. I encourage you to dive deep into the weekend-consuming, infuriating rabbithole that is clean code. You’ll come out of it as a better developer and a better engineer.
Part 3:
Clean Code Series – Part 3: Clean, Readable Code
How to assess your clean code skills?
Geektrust’s coding challenges are not the average coding tests. They are challenges designed to test real-world coding skills – how you can write clean, readable, maintainable code – the kind you’d write while working at a company. No unnecessary DS or algorithm tests, no hard deadlines, no competition or leaderboards. Take your time, craft your solution and write your best code ever in your own IDE — one challenge is all you need to solve.
When you submit code, we evaluate it and give you detailed feedback on what you did well, what you can improve and how to go about it. Some of the top tech companies in the world like ThoughtWorks and Intuit believe in clean code to hire talented developers. When you’re looking for a job, you can showcase your coding skill to 100+ companies hiring on Geektrust. Get started with a challenge to see all this for yourself!
Nice Explination
Poor writeup without demonstrating the code examples. Instead of writing such long paragraphs, writer should have demostrated BAD and GOOD code examples.
Sorry, you’ve had this experience. However, it’s not possible to cover all of this in one article. So we have multiple resources, live sessions and more info throughout our website and help.geektrust.in. Do check these out and let us know if you have any specific questions, or what is not clear. We’ll be happy to help.